Robots.txt is one of the most-used files on the internet. It is found in the root directory of many popular websites. Is it necessary? It depends. You can control indexation using HTML meta tags, but some things related to a website can be handled only with a robots.txt file. We have discussed these things below.
You can control the crawling speed
A few years back, you could have simply added a crawl-delay rule to the robots.txt file to control the crawling speed of Google, but this rule is not supported by the search engine giant right now. This is because Google Search Console allows users to control the rate at which they crawl the pages of your website.
Bing Webmaster tools also allow you to set crawling speed. What about other bots? If your site is hosted on a slow or shared server and a bot tries to crawl 100s of pages of your website within seconds, your server’s CPU and memory usage will spike. You can add a crawl-delay rule because many search bots support it. For example, Ahrefs supports the crawl-delay directive.
You can bad robots
Sometimes, you may not want certain search bots to crawl any page or a specific page or pages of your website. Although you can block the bot’s IP address with the help of a firewall, not all hosting companies, let you add custom firewall rules. SEO plugins don’t let you block certain bots from crawling your website, but robots.txt enables you to do so. The disallow directive in this file tells bots not to crawl your website.
You can block pages
Some pages of a website may have very little content or duplicate content. For example, WordPress categories or tag pages show post excerpts. The excerpt is nothing but a few lines of a paragraph of the post to which the excerpt is linked. Keeping these pages out of search results is good practice.
If you don’t want search bots to crawl and index a page or pages belonging to a specific category on your website, you can configure the SEO plugin to add meta robots “noindex” tag to the page/post or use the “disallow” directive. SEO plugins are available only for content management systems. For example, you can install an SEO plugin for Joomla, Drupal, or WordPress. If you don’t use a CMS, you can manually add the robot’s meta code to a page responsible for displaying the content or showing duplicate content.
You can make search bots aware of the sitemap
If a site is poorly structured, search bots may never find or reach some pages of your website. This is when the sitemap comes into the picture. A sitemap is an XML document that has links to all pages of a website.
Yandex/Bing Webmaster Tools and Google Search Console allow users to submit sitemap files. What if you don’t create an account with these services? To make bots aware of the location of the sitemap on your website, you can use a robot.txt file and Sitemap directive i.e. if your site has this file, you can simply add a link to the sitemap in front of the Sitemap directive in this file.
What if you’re using robots.txt?
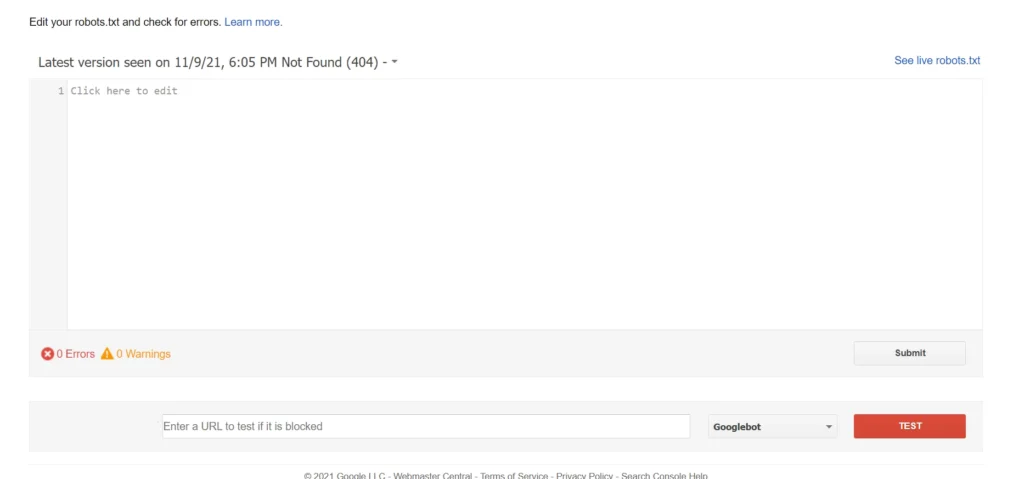
Once you modify the file, you should test the rules. The best tool to do so is Google Search Console’s robots.txt tester. This tool loads the content of robots.txt and shows the same in a large text area. Below the text area, you’ll find a text box. Enter the URL of your site’s page and click the red-colored button with the label test.
Is robots.txt necessary?
Unless your application is well-designed and all links to the pages of your website are reachable from the home page, you should use the file.
